[Source]: A Reading List [0]; The Promise & Pain of Multi-Agents

Feeling Multi-Agent Devs' Pain
“[Source]: A Reading List” isn’t a standard blog post. It’s a format to share papers I found interesting that I find also work together to draw some interesting conclusions when you bounce them off one another. I’m going to only scratch the surface and greatly simplify all the papers listed here. It’s the reason this is called a reading list, there's so much more gold in the sources! Read the ones that seem interesting. It’ll be worth it.
There have been a lot of absolute bangers put out about Multi-Agent Systems this year, but as I went to create a talk, “Feeling Multi-Agent Devs’ Pain,” about multi-agent systems in mid-June an absolute deluge of really interesting articles and papers were published on the topic. The flow hasn’t slowed down since. I decided this might be a fun first list. I hope it provides you some value and insight, let me know how that works out and what might work better.
Multi-Agent Systems
The idea is simple. Multi-Agent Systems decompose complex queries into smaller tasks in order to overcome single LLM agents’ limitations through parallelization, token maximization, and task-based routing to specialized models and tooling.
My path into multi-agents started with my early obsession with the MinionS paper [0]. I loved it so much that I vibe coded an Open WebUI function for both the Minion and MinionS protocols that were reducing my API token spend by over 70% for complex queries and more than 85% for simpler queries (by teaming the frontier model with local agents running in parallel on my laptop at Claude’s command.)
[1] https://arxiv.org/pdf/2503.13657 (4/25) Why Do Multi-Agent LLM Systems Fail?

Right off the bat, this was going to be the lead article for my slide deck, too. Not only are the stats morbid, but they actually developed a taxonomy (MAST) of failure types for multi-agent systems that is actually really useful. I ran into all of the most frequent problem types from their study in building out my system. Beyond that, I can’t think of an issue I had that can’t be categorized by their taxonomy!

Next up, two articles that came out the week before I started writing my talk. And, if you take them in as titles, you’d be surprised to find out that they don’t disagree as much as their titles might suggest.
[2] https://cognition.ai/blog/dont-build-multi-agents (6/25) Don’t Build Multi-Agents
This is a great read for anyone building multi-agents. In it, the makers of Devin describe the evolution of the various attempts and failures at differing architectures and how they settled on the one they did. Lots of great context and advice. The only advice I would not take from this piece comes from the title itself.
Cognition is clearly referring to building coding agents. It’s the example they use for their piece’s multi-agent flows and it’s what they as a company do – it’s safe to assume as much.
[3] https://www.anthropic.com/engineering/multi-agent-research-system (6/25) How We Built Our Multi-Agent Research System
While Anthropic does go out of their way to point out the many benefits of multi-agent systems in their article from the same week, they do also make a concession, “For economic viability, multi-agent systems require tasks where the value of the task is high enough to pay for the increased performance. Further, some domains that require all agents to share the same context or involve many dependencies between agents are not a good fit for multi-agent systems today. For instance, most coding tasks involve fewer truly parallelizable tasks than research, and LLM agents are not yet great at coordinating and delegating to other agents in real time.”

Conclusion 1: Don’t build parallelized multi-agent coders.
Even the first paper I shared [1] seems to be making the same conclusion. How so? Most of their horrible numbers were against coding benchmarks! So, maybe the first definite conclusion we can make from these three in our reading list is “Don’t build parallelized multi-agent coders.”
There are clearly use cases that are bad for multi-agents, and the consensus is that the problems to avoid are:
Tasks that aren’t easily parallelizable (like coding)
Tasks requiring tight integration
Problems with clear, linear solutions
Problems that aren’t of high enough value to justify the high token expense
But, you might also note my choice of words, more specifically the word, “parallelized.” That’s because there are gains to making an agent which has access to sub-agents that it can call on to take a task for it, hand back the results, and move on to the next item in a linear flow.
Anthropic proves this with Claude Code, an agent that does not parallelize tasks, but it does now have a sub-agent system! This provides two big benefits:
Maintaining coherence longer into the session. You can lengthen the primary agent’s context window by allowing the subagent to do a lot of thinking and churning on a specific task, leaving the lead agent’s context cleaner without the context of doing all the intermediary iterations, etc.
Specialization of the agent solving the problem. You can hand off tasks to agents with specialized fine-tuning, tooling, and/or knowledge.
Conclusion 2: What are the good multi-agent problems?
Multi-agent systems excel at problems that are:
Unpredictable and of high-complexity
Highly parallelizable without tight interdependencies between threads
Information-intensive beyond single context windows
Requiring numerous specialized tools
Good candidates include:
Due diligence and market research
Medical literature analysis
Multi-jurisdiction regulatory mapping
Content analysis across languages and markets
System architecture exploration

Conclusion 3: The keys to success with multi-agents
Anthropic's analysis reveals that 95% of performance variance in multi-agent systems comes down to three factors:
Token usage (80% of variance alone)
Number of tool calls
Model choice
Throwing more tokens and tools at a problem can help a lot, but it's expensive. Make sure the juice is worth the squeeze.
Both sources [2] & [3] converge on three critical principles for success.
1. Share Context. Information loss between agents is a primary failure mode.
2. Actions Carry Implicit Decisions. Every action an agent takes embodies assumptions that may conflict with other agents' assumptions. Without explicit coordination, these conflicts compound into system failures.
3. Tool Design Is Critical. As Anthropic puts it: "Agent-tool interfaces are as critical as human-computer interfaces." Bad tool descriptions can send agents down completely wrong paths.
Conclusion 4: The gap between prototype and production is wider than you think
The gap between prototype and production is wider than many anticipate. As Anthropic notes: "Codebases that work on developer machines require significant engineering to become reliable production systems."
The future of multi-agent systems is bright, but we're still in the early, painful stages of figuring out when and how to use them effectively. Understanding these limitations is the first step toward building systems that actually work.
The Rise of Context Engineering
In source [2], Cognition proposes that “Context Engineering” is the new paradigm for agent builders. “In 2025, the models out there are extremely intelligent. But even the smartest human won’t be able to do their job effectively without the context of what they’re being asked to do. ‘Prompt engineering’ was coined as a term for the effort needed to write your task in the ideal format for a LLM chatbot. ‘Context engineering’ is the next level of this. It is about doing this automatically in a dynamic system. It takes more nuance and is effectively the #1 job of engineers building AI agents.”
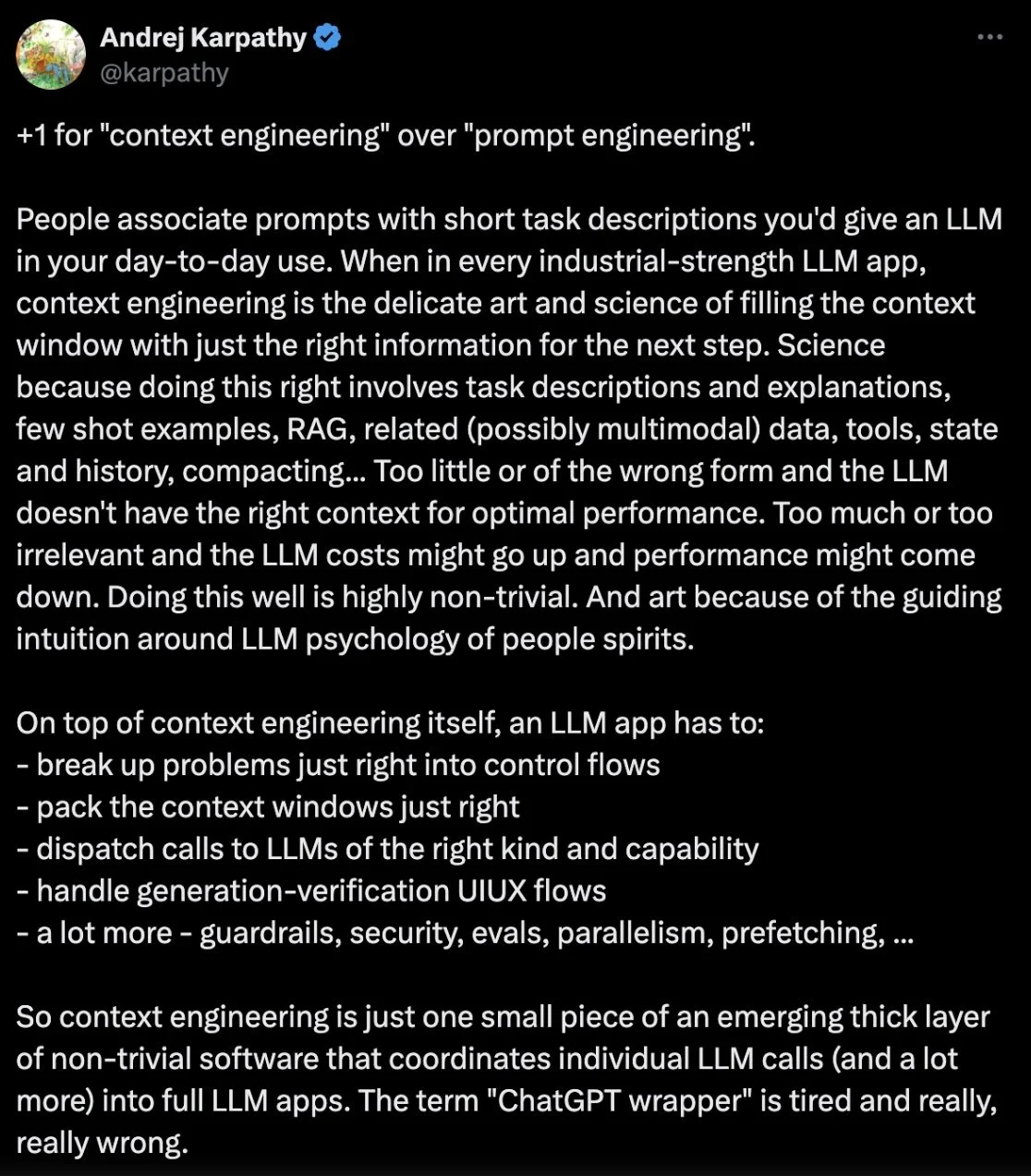
Since then, Context Engineering has completely blown up, thanks in part to the above tweet Andrej sent a couple weeks after that post by Cognition.
[4] https://arxiv.org/pdf/2507.13334 (7/25) A Survey of Context Engineering for Large Language Models
This one source could send you on an endless binge reading of more than 1400 additional sources. Sure, Andrej called Context Engineering “just one small piece” of the software that coordinates LLM calls into LLM Apps, but it is not as tiny as you might expect.

This is another great illustration of “Conclusion 4: The gap between prototype and production is wider than you think.” What starts out so simply can quickly turn into needing to learn a lot of new concepts and weigh a slew of nascent technologies against each other.
Conclusion 5: Context engineering is serious business
I plan to attempt to do a deep dive into the practical meta for Context Engineering in my next reading list. It’s an emergent expertise that didn’t exist formally in “The Meta” long ago. There are many players jockeying for position within it, and we have come so far from Prompt Engineering quite rapidly. The one thing I am sure of, “context engineering is serious business.”
Summary
[5] https://arxiv.org/pdf/2507.21206 (7/25) Weaving the Next Web
There is so much potential promise in Multi-Agent systems. Some even imagine that the “Next Web” will be the “Agentic Web.” They cover all the bases and even provide a roadmap to this Agentic Web. As always it’s Part 8 for me, the “Challenges and Open Problems.” And, here they have provided us another taxonomy for our scanning pleasure:

So, what do I think?
It does seem likely to me that agents and multi-agent systems are the killer business utility of the AI tech era. What shape that will take is greatly up for debate, I couldn’t begin to speculate myself. But, it does mean that there’s a lot of technology left to be built, advances to be made, and standards to define for them to become mainstream and dependable.
If you think you’re late to the game when it comes to agents, I assure you—the game has yet to begin. As Cognition rightly points out, we’re all still figuring this stuff out and the lack of standards in the space is glaring.
There is so much interesting information and technology coming out every day in this space. If anything, the frothiness of the space and its lack of standards means the majority of potential agent developers (as well as the customers for their agents) are still standing on the sidelines.
The best time to learn and make mistakes is always right now.
Reading List #0
[0] https://arxiv.org/pdf/2502.15964 (2/25) Minions: Cost-efficient Collaboration Between On-device and Cloud Language Models
[1] https://arxiv.org/pdf/2503.13657 (4/25) Why Do Multi-Agent LLM Systems Fail?
[2] https://cognition.ai/blog/dont-build-multi-agents (6/25) Don’t Build Multi-Agents
[3] https://www.anthropic.com/engineering/multi-agent-research-system (6/25) How We Built Our Multi-Agent Research System
[4] https://arxiv.org/pdf/2507.13334 (7/25) A Survey of Context Engineering for Large Language Models
[5] https://arxiv.org/pdf/2507.21206 (7/25) Weaving the Next Web with AI Agents